基本理解了 使用大模型查询本地数据 的流程:
- 先把本地数据,切割成一小块一小块存储,并计算其向量。方便理解,假设这些数据总共有 10G。
- 用户查询时,先根据问题,从本地数据库里查询关联的内容,比如 20K。
- 把这些关联内容,作为上下文背景知识,和原始问题,一起传给大模型提问。
- 大模型用自己的能力,结果关联的内容,给出回答。
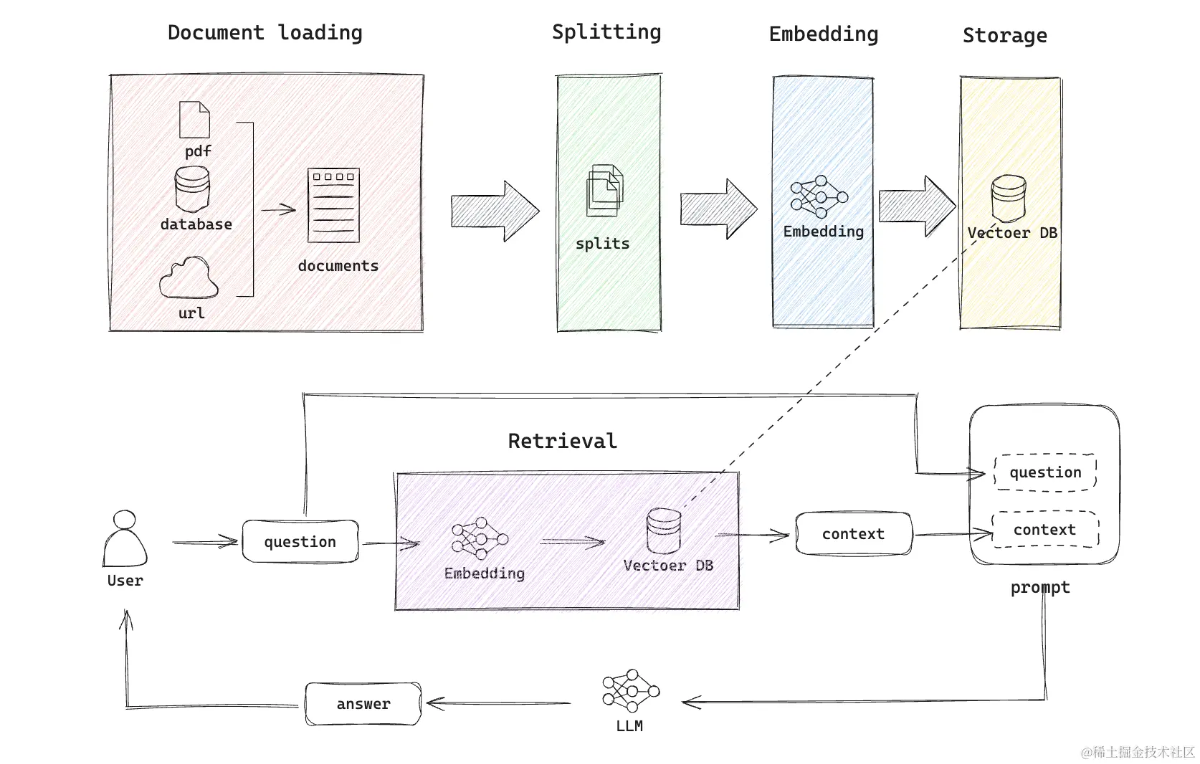
比如,把《消费者权益保护法》作为背景知识,和问题「买东西商家不退货怎么办?」一起丢给大模型。
关键的点:
- 如果使用 ChatGPT 等模型,很贵很花钱,因为每次都丢一大堆上下文。
- 如果使用本地大模型,受限于模型质量,回答可能比较差;受限于算力,会比较慢。
还有一种方式,是用自己规范化的数据,对大模型进行再训练、微调,成为自己行业内的大模型。
基本上,这条路不是一般人能搞得起的。
- 把杂七杂八的数据,规范成统一的格式,比如问答,无比消耗人力物力。高质量、规范化的数据,是成本最不可控的环节。
- 模型的训练,这又有两条路:一条是训练公有大模型比如 OpenAI,按量付费;一种是自己买硬件、训练自己的本地大模型。都费钱。
如果做出来只是给自己用,基本不划算。
如果做出来可以给行业内的人用、把能力二次销售,有可能可行。
后来注意到,OpenAI 的 Assistants 比较符合需求:可以上传最多 10万个文件、100GB 的数据,然后使用 GPT3 或 GPT4 等模型,从中给出答案。
简单试了下,把我的博客、flomo 笔记导入,然后针对性的问问题,确实能得到本地数据中的答案。