先上图:
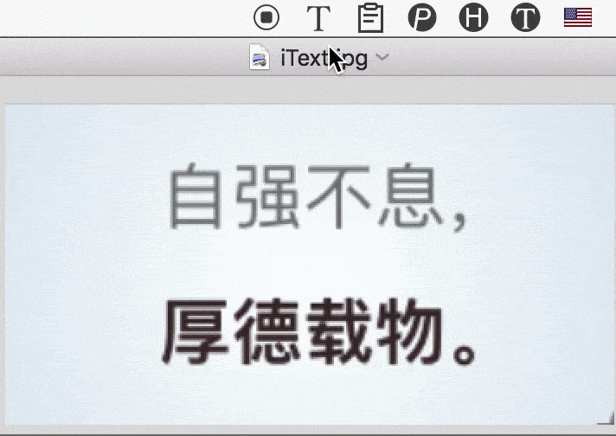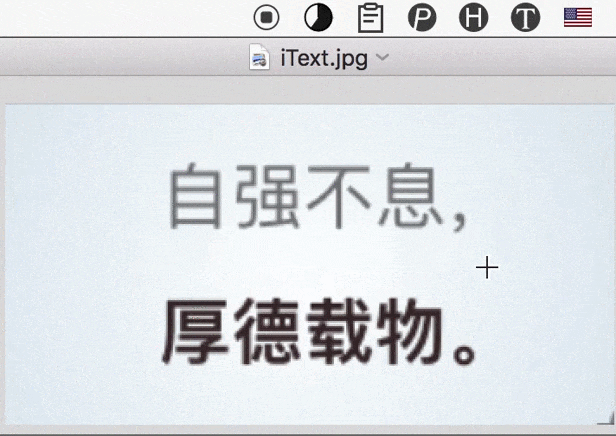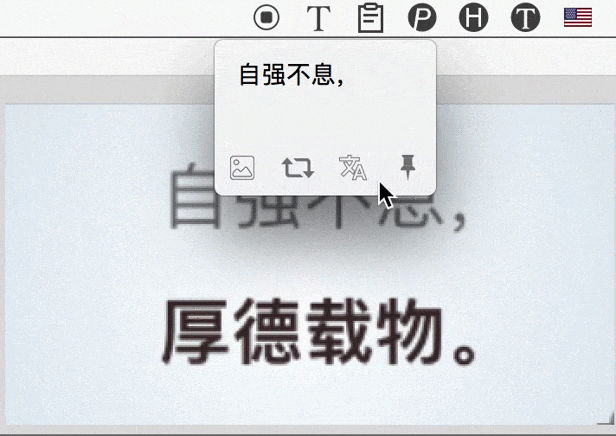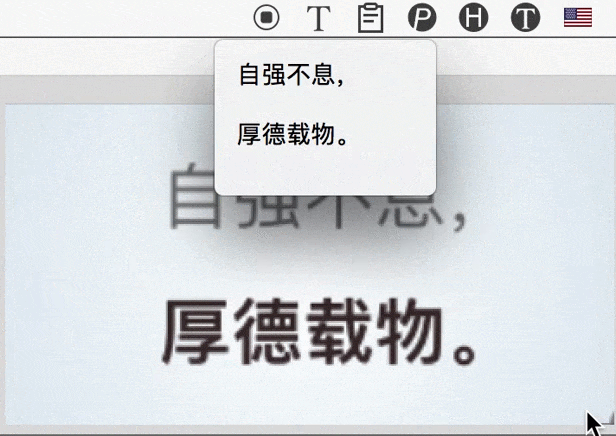
主要要解决的是此类问题:比如,有时会需要识别 PDF 这种排版复杂的「图片」,如果直接把整张图拿去识别,结果肯定会有很多杂音;手动去除这些杂音,也是挺花时间的。
现阶段,更好的办法是「人机配合」;即,自己挑着选中有意义的区域进行文字识别,然后把分别得到的结果拼接出来。而为了实现这一目的,iText 的连续识别、自动拼接识别结果,就会显得很方便。
先上图:
主要要解决的是此类问题:比如,有时会需要识别 PDF 这种排版复杂的「图片」,如果直接把整张图拿去识别,结果肯定会有很多杂音;手动去除这些杂音,也是挺花时间的。
现阶段,更好的办法是「人机配合」;即,自己挑着选中有意义的区域进行文字识别,然后把分别得到的结果拼接出来。而为了实现这一目的,iText 的连续识别、自动拼接识别结果,就会显得很方便。