
0) iText 点子的由来
开始时,我打算在 Klib 中支持从 PDF 导入标注,发现很难;在这个过程中,一些用户提出(发现需求):在看 PDF 文档时,有些扫描版不支持复制文字,不方便。于是,就从双 11 晚上开始,我花了一天,做了 iText 第一版(最小原型),可以截图并从中识别文字。

之后,在微博等渠道做了简单推广,并限制 封闭内测(即,用户需要发邮件给我,才能收到 iText 的下载链接),发现还是有不少人对这个工具感兴趣。这也算是 验证了这个需求的真实性,于是就决定好好做成一款产品。
其实,在开发 iText 时,我已经有包括 Klib 、iPic 在内的 7 款产品。要开一个新坑,还是很慎重的。毕竟,麻雀虽小、五脏俱全;再小的产品,也需要 Logo、产品首页、提交上架、运维等一系列事情。很容易分散精力,做出一款自己都不满意的产品。不过,感觉 iText 应该是可以做的,虽然我当然压根就没做所谓的竞品分析、市场容量分析等等。
1) 我主要做了什么事
2017 年双 11 写下第一行代码,时月 29 号正式上架 Mac App Store,第一版花费将近 20 天的时间。
1.0) 开发最小原型,用了 1 天
虽说第一版最小原型,也已经包含了很多因素,主要是开发相关:
- Logo、图标
- 菜单栏图标基本程序
- 集成百度 OCR 服务
- 剪贴板操作
- 截图功能
- 拖拽
- 界面
- 日志
- 收集反馈
- 试用机制
- 检测更新
- 本地化
- 测试用例、测试
- …
1.1) 完成产品并发布,却用了 20 天
最小原型距离成熟的产品,还有很远的距离,尤其有非常多开发之外的工作:
- Logo 设计
- 集成多家 OCR 服务
- 目前,技术上实现了对接百度、腾讯、Google 的 OCR 服务,最终使用的是后两种。
- 其中,还要压缩图片以满足 OCR 服务对图片尺寸的限制。
- 优化识别结果
- 第一版只是把 OCR 服务返回的结果直接呈现给用户,但识别后的优化,还有大量的工作要做。
- 优化交互
- 第一版只是用 Popover 的方式呈现结果。但通常用户对识别结果有进一步的要求,比如拖拽至原始图片附近、显示原图方便校对等等。这就需要对识别窗口进行优化。
- 另外,用户识别的内容有多有少,固定的窗口大小就显得不合适,这就需要根据内容多少来调整窗口大小。
- 新用户引导
- 实现免费 + 内购(订阅)模式
- 单单是选择哪种付费模式,我就纠结了很久。
- 在限制免费版功能时,还要防止被破解,哎…
- 程序本地化
- 目前支持英文和简体中文。
- 错误处理和日志系统
- 适配不同操作系统
- 目前支持 macOS 10.10+;其中,10.10 的支持有些麻烦,因为有些 API 仅在 10.11 及更新的系统上都有。
- 还要适配 Dark 模式、菜单栏隐藏模式。
- 沙盒模式
- 这里提一点,我是调用系统
/usr/sbin/screencapture进行截图的,而 Mac App Store 默认是不允许的。这时,需要在沙盒配置文件中加com.apple.security.temporary-exception.mach-register.global-name: com.apple.screencapture.interactive的规则。
- 这里提一点,我是调用系统
- 上架 Mac App Store
- 应用描述、关键字、截图等。其中,截图的制作很花时间,既需要设计、又需要具体实现。
- 尤其是,与审核员斗智斗勇…
- 各种文案
- 尤其是设计教程中的操作动画,非常耗时。
下面,在这些环节中,我挑些重要的环节,掰开了、揉碎了说说。
2) 文字识别的核心:OCR
2.0) OCR 是项活化石技术
OCR (Optical Character Recognition) 其实是非常「久远」历史的话题。说久远,是相对于软件的发展速度,OCR 已经存在了好多年。而且,由于一直也都有这样的需求,对应的方案也在不断变化。
- 没几年之前,基本都是 SDK、离线库,卖高昂的售价,通常都是卖给大企业。
- 后来,License 也变也了订阅式的。
- 直至今日,又变成了云端服务化,按使用量收费。
- 甚至,云端这个词都要过时了,慢慢套上了「深度学习」、「AI」这些闪耀的词汇。
随着这些形态的演进,站在台前引领风骚的主,也在不断更迭。比如,之前一直被「百度更懂中文」「微软这种外企肯定更懂英文」这种思想紧紧套住。可后来一试腾讯的 OCR,发现某些图片的识别,中文比百度强、英文比微软强。以及,在技术方面生猛突进的 Google,都让 OCR这个领域不断发生变化。
2.1) 腾讯、Google 双引擎
如何选择 OCR 的技术方案呢?
首先,我排除了离线的识别库,因为离线注定了这些库的识别能力是死的,不会自己增强。
接下来,在一票在线 OCR 服务中,我对比了百度、腾讯、微软、Google 这些四家大厂的产品。最后,在少量测试和主观感受下(比如,Google 信仰的加持,使得即使不测试,我就相信 Google 的 OCR 是很牛的),我最终选择了腾讯、Google 的服务。简单的说,如果你在国内使用 iText,默认使用的是腾讯的服务;国外则使用 Google.
那么,到底识别准不准呢?这么说吧:
- 对于一般的自然语言,比如书中的一段话、新闻稿,识别效果是惊人的准确,甚至可以达到 100%
- 对于排版复杂、尤其有特殊字符的文字,比如程序代码、选择题,识别效果就不太理想,需要手动对识别后的结果进行修正
- 比如,单纯地给一个竖线,机器是无法区分到底是小写的 l、还是大写的 I(顺便问一下,你看出二者的区别了吗?);相反,机器是需要根据上下文进行判断和优化的。而像程序代码这种非自然语言,目前机器是很难进行语义识别的。
- 手写识别?还很遥远
- 期间,还有件有意味的事:有个朋友拍了一张医院病历上的神仙字体,问 iText 能不能识别。看到那歪歪扭扭的线条,能称为是字吗?无奈,现在中文手写的 OCR 基本还处于不可用的状态。少量测试过微软英文的手写识别,够强可用,但也得看潦草的程度。
到底准不准?欢迎你来试试。
顺便说一句,在接入各大服务的 REST API 接口后,明显感觉 Google 的接口最合理:不限制图片分辨率、仅限制原图大小。百度则相对差一些:限制图片分辨率且有 Bug、根据 base64 编码来限定图片大小。
2.2) 永无止境的段落识别
OCR 服务识别后,可以得到这样的结果:各文字片断及其位置。

但,如果根据这些信息还原出自然语境下的段落?这是很难的。我自己试着列出常见的段落分布,分析其中的位置规律,实现相应的识别段落的算法。并且,根据自己和用户测试的图片,根据识别结果对算法进行优化,还是有些效果的。
不过,并不完美。主要是,一些场景下,除非结合语义识别,否则是无法仅根据位置信息来划分段落的。
期间,我还花了 1 天左右的时间 识别多栏。

虽说最后也差不多实现了,但却增加了程序的复杂度,让其它一些原本很简单的问题,变得难以解决。经过一番思考后,我还是删除了这部分代码,仅保留了普通段落的识别。回过头来看,之前决定做多栏识别的决定并不正确。因为这明显优先级低,又需花费大量时间。毕竟,还有很多其他更基础、更重要的事要做。
2.3) 更加永无止境的文本优化
首先要知道 文本优化正确的规则 是什么,比如:
- 空格
- 中英文之间需要增加空格
- 中文与数字之间需要增加空格
- 数字与单位之间需要增加空格
- 全角标点与其他字符之间不加空格
- 标点符号
- 不重复使用标点符号
- 破折号前后需要增加一个空格
- 全角和半角
- 使用全角中文标点
- 数字使用半角字符
- 遇到完整的英文整句、特殊名词,其內容使用半角标点
这里主要参考的是 稀土所翻译的文章排版的规则,在此致谢。
如果说段落识别很麻烦,文本优化则更多麻烦,根本的原因在于:需要对内容进行识别。比如:
- 英文段落首字母大写,这规则没错吧,但对于 “iPhone is a good phone.” 这样的情况,iPhone 是特定词汇,i 不应该大写。
- 中文文字后的 ‘.’ 应该使用全角的 “。”,这规则也没错吧,但对于『今天天气真热啊…』,明显又不应该替换;亦或是 JSON 数据『”name”: “张飞”』中的 “ 也不应该被替换。
- 以及其他无数多的例子。
没办法,只能有所取舍。目前,iText 主要完成了这些部分的优化:
- 自动识别段落
- 中文环境使用全角标点符号
- 中文与英文字母、数字间增加空格
- 删除中文字符间、英文字符与标点符号间的多余空格
- 英文首字母大写
技术方面,主要是使用 正则表达式 来识别并替换。不过,规则越多,正则表达式也越复杂,稍微改动下某条表达式,可能会破坏其他的。甚至,正则表达式之间的顺序,对优化结果也有影响。且表达式多了,也会降低执行效率。还得再想想如何优化。
这里要提一句 单元测试 了。我每实现一条规则的优化,就会补全对应的测试用例。接着再实现下一条则,这些单元测试可以忠实地保证新的规则没有破坏旧的规律,很是有用。
3) 开发过程中的一些感想
下面是一些零散的、我觉得值得拿出来跟大家分享的一些点。
3.0) 名字与 Logo
一提 Logo 就扎心…
在我已发布的产品中,只有 Klib 的 Logo 是朋友 Allen 设计的,也只是这个没被骂过丑。其它均是我自己用设计,都被吐槽过…
这次,我找了位设计师帮忙,前后也设计了好几版:

不过,可能时间有限,没找到打动自己的那款,只能沿用 i 系列的风格。开始时,是这样的:

后来,「精心」设计了颜色,便是文章开头的样子。先这样吧,之后会考虑 i 系列家族统一更新。
至于名字,你一看我之前的产品,应该也会很自然地想到:iText(顺便说一句:Klib 之前其实是叫 iKindle,可惜苹果不允许名字中包含 Kindle 这个商标,只能被迫改名 Klib)
3.1) 新用户引导
这事的矛盾之处在于:新用户和老用户的矛盾。
进一步说,我追求程序的简洁。尤其是在用户对 iText 熟悉之后,并不需要程序有过多的描述。比如,文字按钮可以被图标按钮取代,用界面上根本看不到的快捷键进行操作,等等。可问题是,熟悉是需要一个过程,新用户需要多次操作后,才能掌握这些甚至有些晦涩的技巧。没有新用户,又何来老用户?
这二者的矛盾,怎么解决呢?
我能想到的办法是:保持界面的简洁(照顾老用户),同时在首次运行时增加提示(照顾新用户)。提示包括:
- 首次通过菜单截图时,提示可以通过快捷键截图。
- 首次展示识别结果时,提示识别内容已复制到剪贴板。
- 首次通过菜单展示识别结果时,提示可通过快捷键展示。
比如:
3.2) 用户越多,公约数越少
比如,对于工具型软件,有人偏好效率,有人喜欢美观。想要二者兼得,怕是很难的事,我自认为没有这样的能力。
可是,转念一想,何必二者兼得?如果我只找到偏好效率的用户,全心全意为他们服务,把他们伺候爽了,不就可以了?至于喜欢美观的用户,简单,让他们选择美观的同类产品不就可以了。弱水三千,只取一瓢饮。
3.3) 要解决的,不是问题本身
在处理 macOS 兼容性时,遇到过一个头痛的问题。
目前,iText 支持 macOS 10.10+,我日常自然是在最新的 10.13 中开发的。发布前,在 10.10 环境下测试时,发现了识别结果窗口布局有严重的问题。定睛一看,原来 Xocde 中早有警告:我使用了只在 10.11+ 平台才支持的布局方式,在 10.10 中自然会有问题。
怎么解决呢?
这个问题本身,是指界面布局有问题。OK,那我就解决布局问题呗。问题是,既然 10.11 引入了新的布局方式,自然是这种方式很有用、很方便。而我要在 10.10 模拟出这么布局,相当于开发了 10.11 的部分新功能,这并不是件容易的事。尤其,事实上 10.10 的支持在我这边优先级很低,只是希望顺带支持,并不希望就此花费大量时间。在已经有些复杂的布局基础上继续加补丁,不是好的办法。
跳出问题本身一想,问题的本质是:为 10.10 的用户展现布局良好的窗口。那,为什么一定要在 10.11+ 已有的窗口基础上解决问题呢,为什么不新做一个窗口呢?既然 10.10 的优先级低,那我就做个简化版的窗口,仅保留最重要的展示结果、复制内容等功能,放弃展示图片预览、钉住窗口等高级功能。界面元素少了,布局就是件很简单的事了。
这就是我的感想:要解决的不是问题本身(布局的问题),而是问题的本质(为 10.10 的用户提供布局良好的界面)。跳出问题本身,往往能发现解决问题本质的更简便的方法。
4) iText 是要赚钱的
iText 一定是款需要付费才能完全使用的产品:
- 在线 OCR 服务是需要付费的,通常是按次收费
- 注:腾讯 OCR 服务目前在内测期,免费;不过收费只是时间问题。
- iText 是商业产品,不是业余爱好
- 作为独立开发者,开发 iText 使用的并不是业余时间,而是我全部的工作时间;不是业余爱好,而是想要养活自己的产品。我需要为花费的时间买单,并支撑自己继续做独立开发者。
4.0) 上架 Mac App Store 时遇到的坑
由于开发和推广方面的考虑,我并未构建自己的序列号及付费机制,目前的产品均未在 Mac App Store 外销售;iText 亦如此。
提交 iText 上架 Mac App Store 被拒了多次,最开始上架时的版本号是 1.0.1,最后成功上架的是 1.1.0…
下面是被拒的一些原因及解决方式:
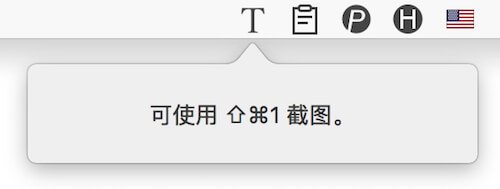
没有在上传用户数据前提示用户
- 其实是这样的,iText 需要上传图片至腾讯、Google 服务器进行识别。而苹果认识这是在上传用户个人数据,需要充分告知用户
- 解决方式:在用户首次上传图片前,简单粗暴地弹个对话框提示:
订阅后没有展示剩余有限期
- 恩,这听着也很有道理。可问题是,我之前 Klib、iPic 中的订阅,也并未提示,为什么审核就能过呢?并且,用户其实是可以在 Mac App Store 中查看这一信息的。哎,这道理没法讲,审核是大爷,想起一出是一出
- 解决方式:显示剩余时间呗
产品不适合「自动」续订的订阅
- 审核员说,「自动」续订的订阅适用于杂志等类型的应用,不适用于 iText 这种功能型的应用。可,同理,为什么之前 Klib、iPic 就可以?依然同理,不可说。
- 解决方式:有点搞笑,我啥都没改。再次提交相同模式的订阅,通过了。也许是换了个审核员、或者审核员的心情变好了。
其实,审核前我还一直担心的一个问题,反而没有被卡:在程序描述及截图中,出现「Google」的字眼。印象中,之前因为出现「Android」被拒,这次倒是侥幸过关了。
最郁闷的是,审核员不会一次告诉我所有问题,而是分批…
- 先用问题 1 把我拒掉
- OK,我改;然后提交新版
- 再用问题 2 把我拒掉
- 如此循环…
另外就是,如果你说:别人家的 App 就是这么干的。没用,在审核员眼里,这并不是你也可以这么干的理由。
上架过程还 吃了几次暗亏,也说出来大伙听听:
- 程序和内购需要分别提交
- 也即,在首次上架时,在提交二进制应用进行审核的同时,也需要「手动」提交所包含的内购项目进行审核。而我遗漏了这一点,导致被拒一次。
- 虽然,我在道理上理解这一逻辑,可苹果明显在提示等方面做得不够好。想我之前也提交过,可这次依然忘了,说明这并没有很强的因果关系,确实是需要提示的。
- 订阅模式改价格,需要提交一天
- 本来,我在 29 号凌晨就审核通过、并自动上架了。可在我将价格改为 6 折时,却发现要到 30 号才能生效。这迫使我不能在 29 号开始宣传,而只能等到 30 号新的价格生效后才行(因为宣传中要提到「首发限时 6 折」这样的字眼),白白浪费了一天,也让首发时间从周三推迟到周四,效果上打了折扣。
另外有一点,大家可能要注意下:新上架、或新版发布、或价格变更时,App Store 的更新需要时间。如果一发布就立马开始推广,用户可能会遇到搜索不到、无法下载、价格未更新、无法升级等奇怪的问题。建议过段时间再推广,比如头天晚上发布,第二天早上开始推广。
4.1) 免费功能到底该如何限制
这是个艰难的决定。
简单的说,如果免费的功能多了,用户就没有付费的必要;如果免费的功能少了,用户可能就要开骂,甚至直接离开,也就谈不上付费了。要把握其中的平衡,着实不易。
另外,除了考虑到收入本身,还要考虑产品的影响力。比如,产品刚发布时,知名度比较小。这时候,用户数量相对更重要些,比较适合 放水养鱼:适当放弃些收入,通过放宽免费功能的限制,来增加用户数量、留住用户。等产品有足够的影响力,就有定价话语权了。
比如,微软对于盗版 Windows、Office 的做法就是典型案例。开始时睁只眼、闭只眼,等大家已经离不开时,就开始向政府、上市企业寄律师函了。
说回 iText,目前免费版未对功能有任何限制,仅限制识别次数。且,每月都有一定的免费额度,使得用户不会刚开始没用几次、一遇到付费就卸载的情况。之后看运行的情况再调整,比如可以调整为每天都有免费次数。
4.2) 说说付费模式
接下来的问题,便是如何确定收费模式。有这几种方式可考虑:
- 买断式
- 也即,你付一次钱,就可终身使用。
- 考虑到 OCR 服务的按次收费,个人觉得这并不科学,至少不具可持续性。
- 流量包式
- 比如,¥12 元买 250 次识别次数。
- 对用户而言,这种方式 对低频使用的用户友好,但对于高频使用的用户,并不太划算。
- 另外,最关键的是,这种方式会给使用上带来很大的心理压力。比如,我在截图时不小心区域没选对,结果白白浪费了一次识别次数,这会让我在每次截图时都会有不小的心理压力,生怕截错了。虽然,从理性的角度,一次真没多少钱。但没办法,这种心里上的事情是很难用理性压住的。
- 包月式
- 也即订阅式,即一个月出固定费用,即可不限次识别。
- 对用户而言,优缺点几乎和流量包式相反:对低频用户不友好、对高频用户友好
- 最终,我选择的是这种模式:每月可免费识别 20 次,充分体验 iText 的功能;订阅高级版即可不限次识别;这样,可以 同时照顾到低频用户和高频用户。首发时 6 折优惠:¥3 每月、或¥30 每年,续费时恢复原价。
其实,这跟手机流量非常像:
- 如果你用量很少,1 MB 流量 0.1 元的方式就很适合你。
- 如果你用是很大、或者就想用得爽,包月得到固定流量、甚至是不限量的套餐,更适合你。
- 不过,我还没见过付一次钱,就可终身不限量使用的套餐。
5) iText 上架后的宣传
其实,这方面我也一直在学习,这里谈不上经验,只是把自己做的事罗列出来。
5.0) 宣传时涉及的渠道
从渠道的角度,大致有这样:
- 用户群
- 微信群
- Telegram 群
- 内测用户邮件列表
- 自己的渠道
- 媒体及第三方
- 少数派
- 知乎
- 掘金
- V2EX
- Price Tag
- Product Hunt
时间有限,我基本上是写通稿,然后针对各个渠道做简单的调整。上面有各渠道对应的文章链接,感兴趣可以点进去看看。其中可见,我做的海外推广很少,这方面求帮带。
其中有个玩法就是:送码。通过这种方式,增加与用户的互动,如留言区的评论、微博的转发等等。
另外,如果你的应用有自己的序列号体系,也可以上「数码荔枝」这样的平台分销,据说效果也不错。可惜我没有序列号,无法触及这些平台。
5.1) 写文案是体力活,也是技术活
上面的每个平台,都需要针对性地写文案。
虽说,好的产品自己会说话、简洁的程序不应该有说明书。可无奈,酒香也怕巷子深,大家在真正使用产品之前,总需要一些方式来了解到产品。而在目前的传播方式中,文案则是必须的了。
这里说的文案,包括:
- 产品本身的说明书、教程
- 发布在媒体上的文章
- 发布在朋友圈等 SNS 上的信息
- 以及其他所有对外爆光的东西
- 除了中文,还有英文…
当然,除了文字,也包括配图、甚至是视频。而这两者,通常比文字更花时间。
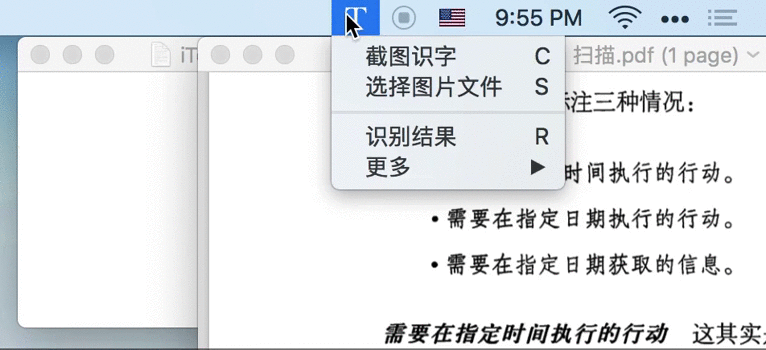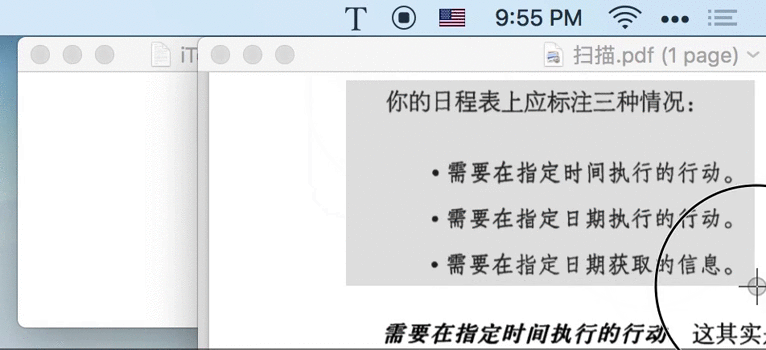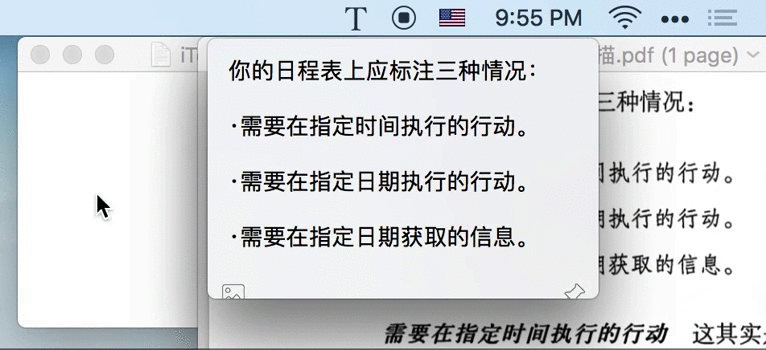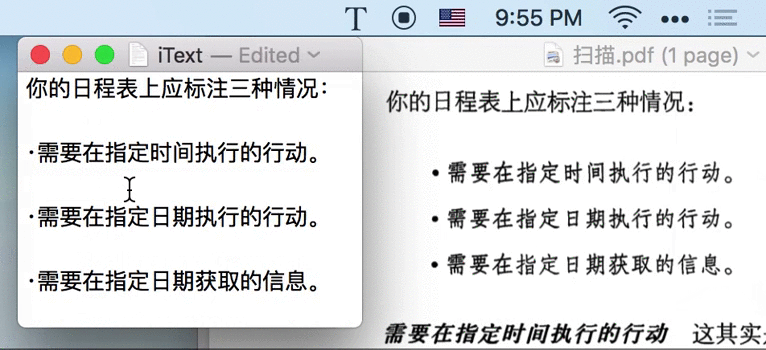
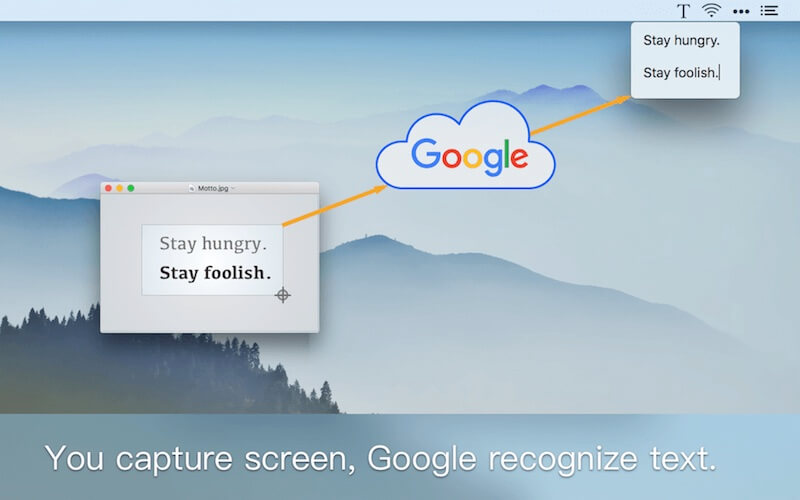
比如,在做上面的图时,首先要明确表达什么、构思如何表达、确定涉及到的素材、录屏、制作 GIF,整个过程流程很多,非常耗时。且一旦需要修改,几乎是全部重来的成本。顺便说一句,如果你想知道上面的 Gif 如何制作,看这里
比如 标题,如果纯粹是反映文章内容,很可能不够吸引人;如果起个抓眼球的标题,又极容易被骂标题党。另外,除了考虑一时一地的点击量,还得从长线上考虑搜索引擎的收录。绝对是技术活。
5.2) 如何量化追踪每个渠道的推广效果
比如,发了一条微博,有多少用户因为这条微博下载安装 iText;进而,这些用户中有多少人付费购买。有了这些量化数据,才能反推出每个渠道的获客成本,进而决定是否要在一个渠道推广、制定推广预算。
可见,量化追踪每个渠道的推广效果,非常重要,因为直接跟钱相关。这里,推广效果最直接的考量是转化率,但又不仅于此。比如品牌的露出、品牌形象的建立,都是要考虑的因素。那么,如何量化转化率呢?可考虑使用 iTunes 联盟。
和其他淘宝客、亚马逊联盟等联盟一样,iTunes 联盟也是苹果为了推动第三方来替自己推广音乐、App 的下载付费,而推出的奖励机制。简单的说,就是你帮苹果销售其音乐、App,苹果会给你一定的的提成。具体到 App,提成比例大约是 0.4%
当然,如此低的提成比例,自然不是我们关心的;我们关心的是渠道转化。比如,在下面的链接中:
https://itunes.apple.com/app/id1314980676?ls=1&mt=12&at=1000lv11&ct=iText_Weibo
其中,1000lv11 是 iTunes 联盟 ID,iText_Weibo 是 需要追踪的事件,也即 iText 在微博上的推广;类似的,也可以有 iText_Twitter,iPic_Facebook 之类的事件。
如果用户通过这个链接安装付费,就可以得到类似这样的数据:1000 人点击微博中的链接、600 人真正安装、20 人付费内购。
授之以渔,我就不在这列 iText 具体的数据了。大家如果需要,可以到 这里 申请 iTunes 联盟。
尾巴
终于,iText 还是顽强上架了(点此下载)。至此,我已集齐七颗龙珠:

iText 接下来会怎样?估计我会根据上架后用户的反馈,在短期内再出个版本。之后,会按住一段时间,直到对更远些的发展想清楚后,再出新版。
我本人接下来会怎样?估计还是会坚持做独立开发者,开发自己的产品,开发世上本没有的产品,用自己的能力,改进大家的效率,哪怕只是一点点。
计划跟不上变化。你明天看到的我,已是不一样的我。